
pip3 install mysql-connector-python
pip3 install mysql-connector-python
1、pip是python的包管理工具,在Python2.7的安装包中,easy_install.py是默认安装的,而pip需要我们手动安装。
打开终端:
sudo easy_install pipcurl https://bootstrap.pypa.io/get-pip.py | python3查看版本
pip --version查看相应的包
pip3 list
安装和更新pip
pip install --upgrade pip
1.匹配文中图片
/<img[^>]*src=”([^”]*)”[^>]*>/i
如果有单引号的情况
(<img[^>]*src=”([^”]*)”[^>]*>)|(<img[^>]*src='([^’]*)'[^>]*>)
2.匹配文中的超链接
/<a[^>]*href="([^"]*)"[^>]*>([^"]*)<\/a>/i
3.匹配URL
(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)
4.其他
| /\b([a-z]+) \1\b/gi | 一个单词连续出现的位置。 |
| /(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/ | 将一个URL解析为协议、域、端口及相对路径。 |
| /^(?:Chapter|Section) [1-9][0-9]{0,1}$/ | 定位章节的位置。 |
| /[-a-z]/ | a至z共26个字母再加一个-号。 |
| /ter\b/ | 可匹配chapter,而不能匹配terminal。 |
| /\Bapt/ | 可匹配chapter,而不能匹配aptitude。 |
| /Windows(?=95 |98 |NT )/ | 可匹配Windows95或Windows98或WindowsNT,当找到一个匹配后,从Windows后面开始进行下一次的检索匹配。 |
| /^\s*$/ | 匹配空行。 |
| /\d{2}-\d{5}/ | 验证由两位数字、一个连字符再加 5 位数字组成的 ID 号。 |
| /<\s*(\S+)(\s[^>]*)?>[\s\S]*<\s*\/\1\s*>/ | 匹配 HTML 标记。 |
只显示目录
ls -l | awk ‘/^d/{print $NF}’
统计文件个数
find ./ -type f -print | wc -l
按扩展名统计文件个数
find ./ -type f | sed -n ‘s/..*\.//p’ | sort | uniq -c
安装报错,百度上找到这个文章保存下,目前官方还没更新,靠这个方法可以解决问题哦
在一些小型项目上需要应用全文搜索引擎时,我比较喜欢使用迅搜,因为部署方便,调用简单,今天给客户部署系统安装迅搜时,竟然有报错(极少遇到报错的情况),花了一些时间查资料,终于解决了,分享一下经验
首先是定位原因,因为我已经在起码五六台Centos主机上安装过迅搜,前面都顺利安装完成了,所以应该是不迅搜本身有什么问题,更大可能是跟运行环境是有关系的,看了一下,目前这台机子安装的是Centos8.0,我之前安装的系统都是7.X的,所以极有可能是和操作系统的版本有关系的。
看了一下在安装界面的信息,内容如下:
bufferevent_openssl.c:237:2: note: (near initialization for ‘methods_bufferevent’)
bufferevent_openssl.c:228:19: error: storage size of ‘methods_bufferevent’ isn’t known
static BIO_METHOD methods_bufferevent = {
^~~~~~~~~~~~~~~~~~~
make[2]: *** [Makefile:793: bufferevent_openssl.lo] Error 1
make[2]: Leaving directory ‘/usr/local/src/xunsearch-full-1.4.14/libevent-2.0.21-stable’
make[1]: *** [Makefile:857: install-recursive] Error 1
make[1]: Leaving directory ‘/usr/local/src/xunsearch-full-1.4.14/libevent-2.0.21-stable’
make: *** [Makefile:1182: install] Error 2
看样子应该是在编译过程中报错了,这个比较棘手,因为这是C写的代码,我总不能直接去改它的源码,于是只能从什么问题导致了编译错误入手,各种查询之后,发现有位网友曾经遇到过这个问题,以下是引用这位网友的内容:
这个问题的原因及解决思路如下:
原因在于libevent 2.0.x需要openssl < 1.1.0
常用的几个Linux发行版已经把系统的openssl升级到了1.1.0+
即对应需要libevent 2.1.x+
而libevent 2.1.x改了头文件.. 如果不更换系统openssl版本.
那就可以去手动下载一个 libevent-2.1.11-stable.tar.gz
自己换成bz压缩格式(libevent-2.1.11-stable.tar.bz2)
放进 packages,记得删掉原来的libevent
作者:一件小毛衣
链接:https://www.jianshu.com/p/2bd166d48f42
来源:简书
后面具体的步骤没有参考他的,因为我和他使用的迅搜版本是不同的,具体解决的方法跟他的有所不同,所以下面继续说我的解决过程:
首先,先去下载一下2.1.X版本的libevent安装包,可以直接搜索libevent,然后在官方的网站上下载,很多时候官方的链接是github上的,如果直接在linux系统上用wget下载有点慢,这种情况下可以先在咱们自己的浏览器上下载好,再通过winscp上传上去,更加快。
我下载的版本是libevent2.1.12,下载链接是:https://github.com/libevent/libevent/releases/download/release-2.1.12-stable/libevent-2.1.12-stable.tar.gz
下载好后上传到服务器上放xunsearch的目录下,我的目录是/usr/local/src/,然后将这个文件解压,并重新压缩成bz2格式,参考代码如下:
//先将libevent解压(以便压缩成所需格式)
tar -zxvf libevent-2.1.12-stable.tar.gz
//压缩成bz2格式,这是迅搜安装包的支持的格式
tar -cjf libevent-2.1.12-stable.tar.bz2 libevent-2.1.12-stable
//复制到xunsearch下的packages文件夹内
cp libevent-2.1.12-stable.tar.bz2 xunsearch-full-1.4.15/packages/
//进入安装包的目录并将原来自带的libevent安装包删除(xunsearch1.4.15自带的是2.0.X)
cd xunsearch-full-1.4.15/packages/
rm -f libevent-2.0.X(删除原来的,我的具体是:
rm -f libevent-2.0.21-stable.tar.bz2)
//返回上一步的文件夹(即迅搜安装包的根目录),然后执行setup.sh就可以了,
//迅搜会自动检查安装包文件内的libevent开头的安装包,如果没找到会报错,如果找到了就会自动解压并编译安装
cd ..
./setup.sh
然后安装过程就愉快地完成了
————————————————
版权声明:本文为CSDN博主「风柏杨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/one_and_only4711/article/details/110926096
1、 n天内修改的(-ctime)
find . -type f -ctime -1| xargs ls –l
说明:
(1) -type f 只搜索文件,不包含文件夹
(2)ctime中的c-change的意思
(3)-ctime +n: n天前修改的;-ctime –n:n天内修改的,修改日期过去n天的
ctime参数指文件日期等状态性参数修改,mtime参数指内容改变:
find . -type f -mtime -1| xargs ls –l
2、n天内访问过的(-actime)
find . -type f -atime -1
说明:
(1) atime中的a-access的意思;
3、 atime、ctime、mtime区别
from: http://blog.csdn.net/abcdef0966/article/details/7607545
(1)atime是指access time,即文件被读取或者执行的时间,修改文件是不会改变access time的。网上很多资料都声称cat、more等读取文件的命令会改变atime,但是我试验时却发现使用cat、more时atime没有被修改。这个问题需要另外做研究探讨。
(2)ctime即change time文件状态改变时间,指文件的i结点被修改的时间,如通过chmod修改文件属性,ctime就会被修改。
(3)mtime即modify time,指文件内容被修改的时间。
4、查看文件的时间等属性
stat./00/00/wKjn3lmeuLqEGxCHAAAAAAAAAAA617.jpg
File: ‘./00/00/wKjn3lmeuLqEGxCHAAAAAAAAAAA617.jpg’
Size: 391552 Blocks: 768 IO Block: 4096 regular file
Device: 801h/2049d Inode: 545906 Links: 1
Access: (0644/-rw-r–r–) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2017-08-24 19:30:13.537917208 +0800
Modify: 2017-08-24 19:30:02.641824935 +0800
Change: 2017-08-24 19:30:02.641824935 +0800
Birth: –
5、以分钟为单位的时间范围查找
与atime,ctime,mtime类似,对应的参数为amin, cmin,mmin
————————————————
版权声明:本文为CSDN博主「hongweigg」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hongweigg/article/details/77552198
mysqldump –default-character-set=utf8 -uroot -p dbname tablename > ~/Downloads/test.sql
mysqldump -uroot -p dbname tablename1 tablename2 |gzip > ~/Downloads/test.sql.gz
centos 下:
1.首先安装epel扩展源 yum -y install epel-release
2. 然后安装pip yum -y install python-pip
3. 安装 bypy :
pip install requests
pip install bypy
4.安装完毕,运行 bypy info
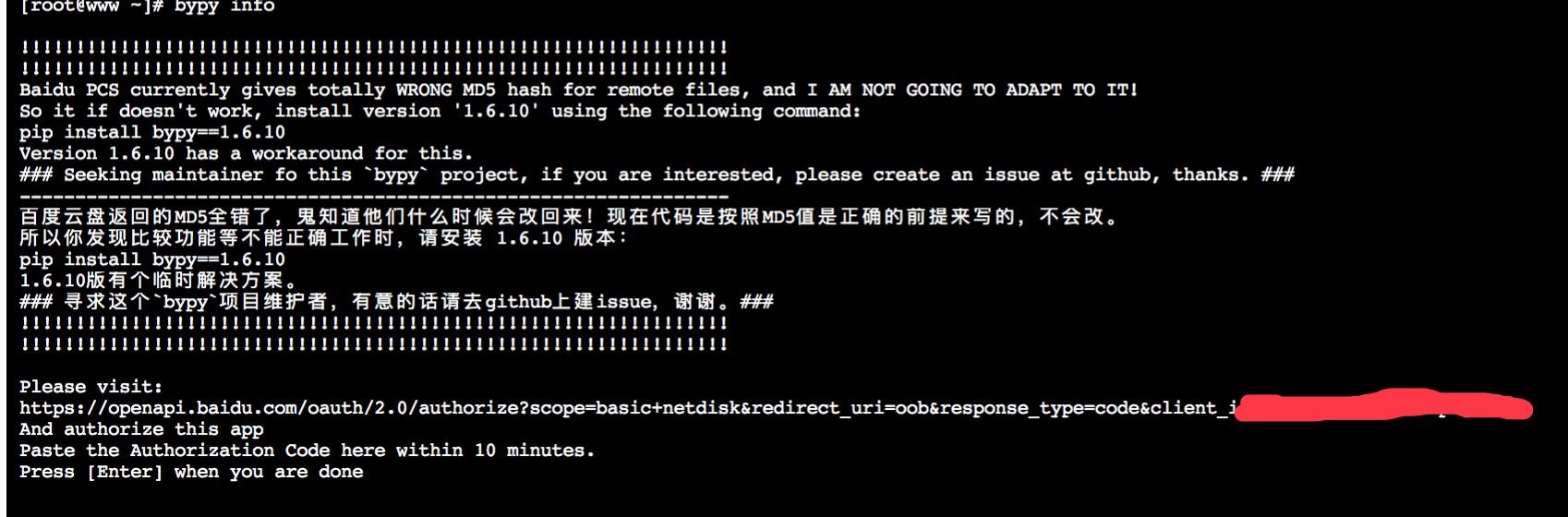
访问上面的 https://openapi.badu.com/oauth/2.0…………这个链接,生成授权码,按照上面的提示粘贴授权码
粘贴后,稍等片刻出现下图:

操作成功了!!!
把本地当前目录下的文件同步到百度云盘:
# bypy upload
把云盘上的内容同步到本地:
# bypy downdir
比较本地当前目录和云盘根目录,看是否一致,来判断是否同步成功:
# bypy compare
一. 前言
逻辑备份和物理备份各有优劣,一般来说,物理备份恢复速度比较快,占用空间比较大,逻辑备份速度比较慢,占用空间比较小。逻辑备份的恢复成本高。
二. 逻辑备份
逻辑备份是备份sql语句,在恢复的时候执行备份的sql语句实现数据库数据的重现。
1)mysqldump
mysqldump是采用SQL级别的备份机制,他将数据表导成SQL脚本文件,是最常用的逻辑备份方法。
三. 物理备份
物理备份就是备份数据文件了,比较形象点就是cp下数据文件,但真正备份的时候自然不是的cp这么简单。
1)使用 xtrabackup 工具
是一个用来备份 MySQL数据库的开源工具。
主要特点:
<1>. 在线热备份。可以备份innodb和myisam。innodb主要应用recovery原理。myisam直接拷贝文件。
<2>. 支持流备份。可以备份到disk,tape和reomot host。–stream=tar ./ | ssh user@remotehost cat “>” /backup/dir/
<3>. 支持增量备份。可以利用lsn和基础备份目录来进行增量备份。
<4>. 支持记录slave上的master log和master position信息。
<5>. 支持多个进程同时热备份,xtrabackup的稳定性还是挺好的。
2)LVM
特点:热备、支持所有基于本地磁盘的存储引擎、快速备份、低开销、容易保持完整性、快速恢复等。
3)cp + tar
使用直接拷贝数据库文件的方式进行打包备份,需要注意的是执行步骤:锁表、备份、解表。
恢复也很简单,直接拷贝到之前的数据库文件的存放目录即可。
注意:对于Innodb引擎的表来说,还需要备份日志文件,即ib_logfile*文件。因为当Innodb表损坏时,就可以依靠这些日志文件来恢复。
4)mysqlhotcopy
mysqlhotcopy是一个perl程序,是lock tables、flush tables 和cp或scp来快速备份数据库。
它是备份数据库或单个表的最快的途径,但它只能运行在数据库文件(包括数据表文件、数据文件、索引文件)所在的机器上。
mysqlhotcopy只能用于备份MyISAM。
5)使用mysql主从复制
mysql的复制是指将主数据库的DDL和DML操作通过二进制文件(bin-log)传送到从服务器上,然后在从服务器上对这些日志做重新执行的操作,从而使得从服务器和主服务器保持数据的同步。
四. 参考出处
《How innobackupex Works》http://www.percona.com/doc/perconaxtrabackup/innobackupex/how_innobackupex_works.html
《使用xtrabackup做数据库的增量备份》 http://www.cnblogs.com/cosiray/archive/2012/03/09/2388113.html
《MySQL备份和同步时使用LVM》 http://imysql.cn/?q=node/102
《三种mysql备份方法》 http://www.doc88.com/p-617721704574.html
《10种mysql备份教程推荐》 http://database.chinaunix.net/a2011/0822/1235/000001235979.shtml
转自:https://blog.51cto.com/horizon49/1163797
另外阿里云上也有关于RDS物理备份和逻辑备份恢复到自建服务器上详细介绍:
转自微信:架构师之路
上一篇《微服务架构,多“微”才合适?》聊了微服务的粒度。微服务离不开RPC框架,RPC框架的原理、实践及细节,是本篇要分享的内容。
服务化的一个好处就是,不限定服务的提供方使用什么技术选型,能够实现大公司跨团队的技术解耦,如下图所示:
服务的上游调用方,按照接口、协议即可完成对远端服务的调用。
但实际上,大部分互联网公司,研发团队规模有限,大都使用同一套技术体系来实现服务:
这样的话,如果没有统一的服务框架,各个团队的服务提供方就需要各自实现一套序列化、反序列化、网络框架、连接池、收发线程、超时处理、状态机等“业务之外”的重复技术劳动,造成整体的低效。
因此,统一服务框架把上述“业务之外”的工作统一实现,是服务化首要解决的问题。
什么是RPC?
Remote Procedure Call Protocol,远程过程调用。
什么是“远程”,为什么“远”?
先来看下什么是“近”,即“本地函数调用”。
当我们写下:
int result = Add(1, 2);
这行代码的时候,到底发生了什么?
这三个动作,都发生在同一个进程空间里,这是本地函数调用。
那有没有办法,调用一个跨进程的函数呢?
典型的,这个进程部署在另一台服务器上。
最容易想到的,两个进程约定一个协议格式,使用Socket通信,来传输:
如果能够实现,那这就是“远程”过程调用。
Socket通信只能传递连续的字节流,如何将入参、函数都放到连续的字节流里呢?
假设,设计一个11字节的请求报文:
同理,可以设计一个4字节响应报文:
调用方的代码可能变为:
request = MakePacket(“add”, 1, 2);
SendRequest_ToService_B(request);
response = RecieveRespnse_FromService_B();
int result = unMakePacket(respnse);
这4个步骤是:
(1)将传入参数变为字节流;
(2)将字节流发给服务B;
(3)从服务B接受返回字节流;
(4)将返回字节流变为传出参数;
服务方的代码可能变为:
request = RecieveRequest();
args/function = unMakePacket(request);
result = Add(1, 2);
response = MakePacket(result);
SendResponse(response);
这个5个步骤也很好理解:
(1)服务端收到字节流;
(2)将字节流转为函数名与参数;
(3)本地调用函数得到结果;
(4)将结果转变为字节流;
(5)将字节流发送给调用方;
这个过程用一张图描述如下:
调用方与服务方的处理步骤都是非常清晰。
这个过程存在最大的问题是什么呢?
调用方太麻烦了,每次都要关注很多底层细节:
能不能调用层不关注这个细节?
可以,RPC框架就是解决这个问题的,它能够让调用方“像调用本地函数一样调用远端的函数(服务)”。
讲到这里,是不是对RPC,对序列化范序列化有点感觉了?往下看,有更多的底层细节。
RPC框架,要向调用方屏蔽各种复杂性,要向服务提供方也屏蔽各类复杂性:
所以整个RPC框架又分为client部分与server部分,实现上面的目标,把复杂性屏蔽,就是RPC框架的职责。
如上图所示,业务方的职责是:
RPC框架的职责是,中间大蓝框的部分:
server端的技术大家了解的比较多,接下来重点讲讲client端的技术细节。
先来看看RPC-client部分的“序列化反序列化”部分。
为什么要进行序列化?
工程师通常使用“对象”来进行数据的操纵:
class User{
std::String user_name;
uint64_t user_id;
uint32_t user_age;
};
User u = new User(“shenjian”);
u.setUid(123);
u.setAge(35);
但当需要对数据进行存储或者传输时,“对象”就不这么好用了,往往需要把数据转化成连续空间的“二进制字节流”,一些典型的场景是:
所谓序列化(Serialization),就是将“对象”形态的数据转化为“连续空间二进制字节流”形态数据的过程。这个过程的逆过程叫做反序列化。
怎么进行序列化?
这是一个非常细节的问题,要是让你来把“对象”转化为字节流,你会怎么做?很容易想到的一个方法是xml(或者json)这类具有自描述特性的标记性语言:
<class name=”User”>
<element name=”user_name” type=”std::String” value=”shenjian” />
<element name=”user_id” type=”uint64_t” value=”123” />
<element name=”user_age” type=”uint32_t” value=”35” />
</class>
规定好转换规则,发送方很容易把User类的一个对象序列化为xml,服务方收到xml二进制流之后,也很容易将其范序列化为User对象。
画外音:语言支持反射时,这个工作很容易。
第二个方法是自己实现二进制协议来进行序列化,还是以上面的User对象为例,可以设计一个这样的通用协议:
上面的User对象,用这个协议描述出来可能是这样的:
整个二进制字节流共12+29+27+24=92字节。
实际的序列化协议要考虑的细节远比这个多,例如:强类型的语言不仅要还原属性名,属性值,还要还原属性类型;复杂的对象不仅要考虑普通类型,还要考虑对象嵌套类型等。无论如何,序列化的思路都是类似的。
序列化协议要考虑什么因素?
不管使用成熟协议xml/json,还是自定义二进制协议来序列化对象,序列化协议设计时都需要考虑以下这些因素。
有哪些常见的序列化方式?
RPC-client除了:
还包含:
这一部分,又分为同步调用与异步调用两种方式,下面一一来进行介绍。
画外音:搞通透RPC-client确实不容易。
同步调用的代码片段为:
Result = Add(Obj1, Obj2);// 得到Result之前处于阻塞状态
异步调用的代码片段为:
Add(Obj1, Obj2, callback);// 调用后直接返回,不等结果
处理结果通过回调为:
callback(Result){// 得到处理结果后会调用这个回调函数
…
}
这两类调用,在RPC-client里,实现方式完全不一样。
RPC-client同步调用架构如何?
所谓同步调用,在得到结果之前,一直处于阻塞状态,会一直占用一个工作线程,上图简单的说明了一下组件、交互、流程步骤:
1)业务代码发起RPC调用:
Result=Add(Obj1,Obj2)
2)序列化组件,将对象调用序列化成二进制字节流,可理解为一个待发送的包packet1;
3)通过连接池组件拿到一个可用的连接connection;
4)通过连接connection将包packet1发送给RPC-server;
5)发送包在网络传输,发给RPC-server;
6)响应包在网络传输,发回给RPC-client;
7)通过连接connection从RPC-server收取响应包packet2;
8)通过连接池组件,将conneciont放回连接池;
9)序列化组件,将packet2范序列化为Result对象返回给调用方;
10)业务代码获取Result结果,工作线程继续往下走;
画外音:请对照架构图中的1-10步骤阅读。
连接池组件有什么作用?
RPC框架锁支持的负载均衡、故障转移、发送超时等特性,都是通过连接池组件去实现的。
典型连接池组件对外提供的接口为:
int ConnectionPool::init(…);
Connection ConnectionPool::getConnection();
int ConnectionPool::putConnection(Connection t);
init做了些什么?
和下游RPC-server(一般是一个集群),建立N个tcp长连接,即所谓的连接“池”。
getConnection做了些什么?
从连接“池”中拿一个连接,加锁(置一个标志位),返回给调用方。
putConnection做了些什么?
将一个分配出去的连接放回连接“池”中,解锁(也是置一个标志位)。
如何实现负载均衡?
连接池中建立了与一个RPC-server集群的连接,连接池在返回连接的时候,需要具备随机性。
如何实现故障转移?
连接池中建立了与一个RPC-server集群的连接,当连接池发现某一个机器的连接异常后,需要将这个机器的连接排除掉,返回正常的连接,在机器恢复后,再将连接加回来。
如何实现发送超时?
因为是同步阻塞调用,拿到一个连接后,使用带超时的send/recv即可实现带超时的发送和接收。
总的来说,同步的RPC-client的实现是相对比较容易的,序列化组件、连接池组件配合多工作线程数,就能够实现。
遗留问题,工作线程数设置为多少最合适?
这个问题在《工作线程数究竟要设置为多少最合适?》中讨论过,此处不再深究。
RPC-client异步回调架构如何?
所谓异步回调,在得到结果之前,不会处于阻塞状态,理论上任何时间都没有任何线程处于阻塞状态,因此异步回调的模型,理论上只需要很少的工作线程与服务连接就能够达到很高的吞吐量,如上图所示:
1)业务代码发起异步RPC调用;
Add(Obj1,Obj2, callback)
2)上下文管理器,将请求,回调,上下文存储起来;
3)序列化组件,将对象调用序列化成二进制字节流,可理解为一个待发送的包packet1;
4)下游收发队列,将报文放入“待发送队列”,此时调用返回,不会阻塞工作线程;
5)下游收发线程,将报文从“待发送队列”中取出,通过连接池组件拿到一个可用的连接connection;
6)通过连接connection将包packet1发送给RPC-server;
7)发送包在网络传输,发给RPC-server;
8)响应包在网络传输,发回给RPC-client;
9)通过连接connection从RPC-server收取响应包packet2;
10)下游收发线程,将报文放入“已接受队列”,通过连接池组件,将conneciont放回连接池;
11)下游收发队列里,报文被取出,此时回调将要开始,不会阻塞工作线程;
12)序列化组件,将packet2范序列化为Result对象;
13)上下文管理器,将结果,回调,上下文取出;
14)通过callback回调业务代码,返回Result结果,工作线程继续往下走;
如果请求长时间不返回,处理流程是:
15)上下文管理器,请求长时间没有返回;
16)超时管理器拿到超时的上下文;
17)通过timeout_cb回调业务代码,工作线程继续往下走;
画外音:请配合架构图仔细看几遍这个流程。
序列化组件和连接池组件上文已经介绍过,收发队列与收发线程比较容易理解。下面重点介绍上下文管理器与超时管理器这两个总的组件。
为什么需要上下文管理器?
由于请求包的发送,响应包的回调都是异步的,甚至不在同一个工作线程中完成,需要一个组件来记录一个请求的上下文,把请求-响应-回调等一些信息匹配起来。
如何将请求-响应-回调这些信息匹配起来?
这是一个很有意思的问题,通过一条连接往下游服务发送了a,b,c三个请求包,异步的收到了x,y,z三个响应包:
怎么知道哪个请求包与哪个响应包对应?
怎么知道哪个响应包与哪个回调函数对应?
可以通过“请求id”来实现请求-响应-回调的串联。
整个处理流程如上,通过请求id,上下文管理器来对应请求-响应-callback之间的映射关系:
1)生成请求id;
2)生成请求上下文context,上下文中包含发送时间time,回调函数callback等信息;
3)上下文管理器记录req-id与上下文context的映射关系;
4)将req-id打在请求包里发给RPC-server;
5)RPC-server将req-id打在响应包里返回;
6)由响应包中的req-id,通过上下文管理器找到原来的上下文context;
7)从上下文context中拿到回调函数callback;
8)callback将Result带回,推动业务的进一步执行;
如何实现负载均衡,故障转移?
与同步的连接池思路类似,不同之处在于:
如何实现超时发送与接收?
超时收发,与同步阻塞收发的实现就不一样了:
超时管理器如何实现超时管理?
超时管理器,用于实现请求回包超时回调处理。
每一个请求发送给下游RPC-server,会在上下文管理器中保存req-id与上下文的信息,上下文中保存了请求很多相关信息,例如req-id,回包回调,超时回调,发送时间等。
超时管理器启动timer对上下文管理器中的context进行扫描,看上下文中请求发送时间是否过长,如果过长,就不再等待回包,直接超时回调,推动业务流程继续往下走,并将上下文删除掉。
如果超时回调执行后,正常的回包又到达,通过req-id在上下文管理器里找不到上下文,就直接将请求丢弃。
画外音:因为已经超时处理了,无法恢复上下文。
无论如何,异步回调和同步回调相比,除了序列化组件和连接池组件,会多出上下文管理器,超时管理器,下游收发队列,下游收发线程等组件,并且对调用方的调用习惯有影响。
画外音:编程习惯,由同步变为了回调。
异步回调能提高系统整体的吞吐量,具体使用哪种方式实现RPC-client,可以结合业务场景来选取。
总结
什么是RPC调用?
像调用本地函数一样,调用一个远端服务。
为什么需要RPC框架?
RPC框架用于屏蔽RPC调用过程中的序列化,网络传输等技术细节。让调用方只专注于调用,服务方只专注于实现调用。
什么是序列化?为什么需要序列化?
把对象转化为连续二进制流的过程,叫做序列化。磁盘存储,缓存存储,网络传输只能操作于二进制流,所以必须序列化。
同步RPC-client的核心组件是什么?
同步RPC-client的核心组件是序列化组件、连接池组件。它通过连接池来实现负载均衡与故障转移,通过阻塞的收发来实现超时处理。
异步RPC-client的核心组件是什么?
异步RPC-client的核心组件是序列化组件、连接池组件、收发队列、收发线程、上下文管理器、超时管理器。它通过“请求id”来关联请求包-响应包-回调函数,用上下文管理器来管理上下文,用超时管理器中的timer触发超时回调,推进业务流程的超时处理。
思路比结论重要。