
2019努力奋斗!!!加油!!!
深入学习Redis集群搭建方案及实现原理
前言
作为一名后台开发,对数据库进行基准测试,以掌握数据库的性能情况是非常必要的。本文介绍了MySQL基准测试的基本概念,以及使用sysbench对MySQL进行基准测试的详细方法。
文章有疏漏之处,欢迎批评指正。
目录
一、基准测试简介
1、什么是基准测试
2、基准测试的作用
3、基准测试的指标
4、基准测试的分类
二、sysbench
1、sysbench简介
2、sysbench安装
3、sysbench语法
4、sysbench使用举例
5、测试结果
三、建议
一、基准测试简介
1、什么是基准测试
数据库的基准测试是对数据库的性能指标进行定量的、可复现的、可对比的测试。
基准测试与压力测试
基准测试可以理解为针对系统的一种压力测试。但基准测试不关心业务逻辑,更加简单、直接、易于测试,数据可以由工具生成,不要求真实;而压力测试一般考虑业务逻辑(如购物车业务),要求真实的数据。
2、基准测试的作用
对于多数Web应用,整个系统的瓶颈在于数据库;原因很简单:Web应用中的其他因素,例如网络带宽、负载均衡节点、应用服务器(包括CPU、内存、硬盘灯、连接数等)、缓存,都很容易通过水平的扩展(俗称加机器)来实现性能的提高。而对于MySQL,由于数据一致性的要求,无法通过增加机器来分散向数据库写数据带来的压力;虽然可以通过前置缓存(Redis等)、读写分离、分库分表来减轻压力,但是与系统其它组件的水平扩展相比,受到了太多的限制。
而对数据库的基准测试的作用,就是分析在当前的配置下(包括硬件配置、OS、数据库设置等),数据库的性能表现,从而找出MySQL的性能阈值,并根据实际系统的要求调整配置。
3、基准测试的指标
常见的数据库指标包括:
- TPS/QPS:衡量吞吐量。
- 响应时间:包括平均响应时间、最小响应时间、最大响应时间、时间百分比等,其中时间百分比参考意义较大,如前95%的请求的最大响应时间。。
- 并发量:同时处理的查询请求的数量。
4、基准测试的分类
对MySQL的基准测试,有如下两种思路:
(1)针对整个系统的基准测试:通过http请求进行测试,如通过浏览器、APP或postman等测试工具。该方案的优点是能够更好的针对整个系统,测试结果更加准确;缺点是设计复杂实现困难。
(2)只针对MySQL的基准测试:优点和缺点与针对整个系统的测试恰好相反。
在针对MySQL进行基准测试时,一般使用专门的工具进行,例如mysqlslap、sysbench等。其中,sysbench比mysqlslap更通用、更强大,且更适合Innodb(因为模拟了许多Innodb的IO特性),下面介绍使用sysbench进行基准测试的方法。
二、sysbench
1、sysbench简介
sysbench是跨平台的基准测试工具,支持多线程,支持多种数据库;主要包括以下几种测试:
- cpu性能
- 磁盘io性能
- 调度程序性能
- 内存分配及传输速度
- POSIX线程性能
- 数据库性能(OLTP基准测试)
本文主要介绍对数据库性能的测试。
2、sysbench安装
本文使用的环境时CentOS 6.5;在其他Linux系统上的安装方法大同小异。MySQL版本是5.6。
(1)下载解压
wget https://github.com/akopytov/sysbench/archive/1.0.zip -O "sysbench-1.0.zip"unzip sysbench-1.0.zipcd sysbench-1.0 |
(2)安装依赖
yum install automake libtool –y |
(3)安装
安装之前,确保位于之前解压的sysbench目录中。
./autogen.sh./configureexport LD_LIBRARY_PATH=/usr/local/mysql/include #这里换成机器中mysql路径下的includemakemake install |
(4)安装成功
[root@test sysbench-1.0]# sysbench --versionsysbench 1.0.9 |
3、sysbench语法
执行sysbench –help,可以看到sysbench的详细使用方法。
sysbench的基本语法如下:
sysbench [options]… [testname] [command]
下面说明实际使用中,常用的参数和命令。
(1)command
command是sysbench要执行的命令,包括prepare、run和cleanup,顾名思义,prepare是为测试提前准备数据,run是执行正式的测试,cleanup是在测试完成后对数据库进行清理。
(2)testname
testname指定了要进行的测试,在老版本的sysbench中,可以通过–test参数指定测试的脚本;而在新版本中,–test参数已经声明为废弃,可以不使用–test,而是直接指定脚本。
例如,如下两种方法效果是一样的:
sysbench --test=./tests/include/oltp_legacy/oltp.luasysbench ./tests/include/oltp_legacy/oltp.lua |
测试时使用的脚本为lua脚本,可以使用sysbench自带脚本,也可以自己开发。对于大多数应用,使用sysbench自带的脚本就足够了。不同版本的sysbench中,lua脚本的位置可能不同,可以自己在sysbench路径下使用find命令搜索oltp.lua。P.S.:大多数数据服务都是oltp类型的,如果你不了解什么是oltp,那么大概率你的数据服务就是oltp类型的。
(3)options
sysbench的参数有很多,其中比较常用的包括:
MySQL连接信息参数
- –mysql-host:MySQL服务器主机名,默认localhost;如果在本机上使用localhost报错,提示无法连接MySQL服务器,改成本机的IP地址应该就可以了。
- –mysql-port:MySQL服务器端口,默认3306
- –mysql-user:用户名
- –mysql-password:密码
MySQL执行参数
- –oltp-test-mode:执行模式,包括simple、nontrx和complex,默认是complex。simple模式下只测试简单的查询;nontrx不仅测试查询,还测试插入更新等,但是不使用事务;complex模式下测试最全面,会测试增删改查,而且会使用事务。可以根据自己的需要选择测试模式。
- –oltp-tables-count:测试的表数量,根据实际情况选择
- –oltp-table-size:测试的表的大小,根据实际情况选择
- –threads:客户端的并发连接数
- –time:测试执行的时间,单位是秒,该值不要太短,可以选择120
- –report-interval:生成报告的时间间隔,单位是秒,如10
4、sysbench使用举例
在执行sysbench时,应该注意:
(1)尽量不要在MySQL服务器运行的机器上进行测试,一方面可能无法体现网络(哪怕是局域网)的影响,另一方面,sysbench的运行(尤其是设置的并发数较高时)会影响MySQL服务器的表现。
(2)可以逐步增加客户端的并发连接数(–thread参数),观察在连接数不同情况下,MySQL服务器的表现;如分别设置为10,20,50,100等。
(3)一般执行模式选择complex即可,如果需要特别测试服务器只读性能,或不使用事务时的性能,可以选择simple模式或nontrx模式。
(4)如果连续进行多次测试,注意确保之前测试的数据已经被清理干净。
下面是sysbench使用的一个例子:
(1)准备数据
sysbench ./tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.10.10 |
其中,执行模式为complex,使用了10个表,每个表有10万条数据,客户端的并发线程数为10,执行时间为120秒,每10秒生成一次报告。
(2)执行测试
将测试结果导出到文件中,便于后续分析。
sysbench ./tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.10.10 |
(3)清理数据
执行完测试后,清理数据,否则后面的测试会受到影响。
sysbench ./tests/include/oltp_legacy/oltp.lua --mysql-host=192.168.10.10 --mysql-port=3306 --mysql-user=root --mysql-password=123456 cleanup |
5、测试结果
测试结束后,查看输出文件,如下所示: 
其中,对于我们比较重要的信息包括:
queries:查询总数及qps
transactions:事务总数及tps
Latency-95th percentile:前95%的请求的最大响应时间,本例中是344毫秒,这个延迟非常大,是因为我用的MySQL服务器性能很差;在正式环境中这个数值是绝对不能接受的。
三、建议
下面是使用sysbench的一些建议。
1、在开始测试之前,应该首先明确:应采用针对整个系统的基准测试,还是针对MySQL的基准测试,还是二者都需要。
2、如果需要针对MySQL的基准测试,那么还需要明确精度方面的要求:是否需要使用生产环境的真实数据,还是使用工具生成也可以;前者实施起来更加繁琐。如果要使用真实数据,尽量使用全部数据,而不是部分数据。
3、基准测试要进行多次才有意义。
4、测试时需要注意主从同步的状态。
5、测试必须模拟多线程的情况,单线程情况不但无法模拟真实的效率,也无法模拟阻塞甚至死锁情况。
本文转自:https://www.cnblogs.com/kismetv/p/7615738.html
redis应用场景
毫无疑问,Redis开创了一种新的数据存储思路,使用Redis,我们不用在面对功能单调的数据库时,把精力放在如何把大象放进冰箱这样的问题上,而是利用Redis灵活多变的数据结构和数据操作,为不同的大象构建不同的冰箱。希望你喜欢这个比喻。
一、Redis常用数据类型
Redis最为常用的数据类型主要有以下五种:
- String
- Hash
- List
- Set
- Sorted set
在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部内存管理中是如何描述这些不同数据类型的:
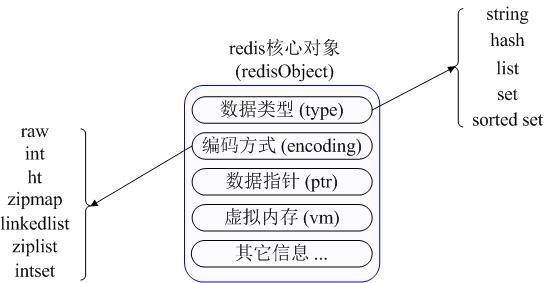
首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:”123″ “456”这样的字符串。
这里需要特殊说明一下vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。通过上图我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给Redis不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用,我们随后会具体讨论。
二、各种数据类型应用和实现方式
下面我们先来逐一的分析下这五种数据类型的使用和内部实现方式:
1、String
String 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字。
常用命令:get、set、incr、decr、mget等。
应用场景:String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类,即可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
- 获取字符串长度
- 往字符串append内容
- 设置和获取字符串的某一段内容
- 设置及获取字符串的某一位(bit)
- 批量设置一系列字符串的内容
使用场景:常规key-value缓存应用。常规计数: 微博数, 粉丝数。
实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2、Hash
常用命令:hget,hset,hgetall 等。
应用场景:
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:

第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
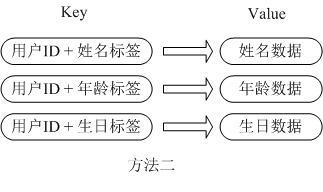
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
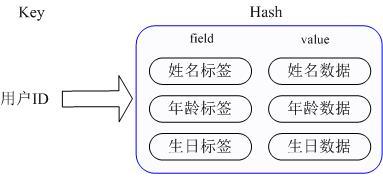
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
使用场景:存储部分变更数据,如用户信息等。
实现方式:
上面已经说到Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
3、List
常用命令:lpush,rpush,lpop,rpop,lrange等。
应用场景:
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
List 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用List结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,
可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
实现方式:
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。
使用场景:
消息队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
比如:将Redis用作日志收集器
实际上还是一个队列,多个端点将日志信息写入Redis,然后一个worker统一将所有日志写到磁盘。
取最新N个数据的操作
记录前N个最新登陆的用户Id列表,超出的范围可以从数据库中获得。
//把当前登录人添加到链表里
ret = r.lpush("login:last_login_times", uid)
//保持链表只有N位
ret = redis.ltrim("login:last_login_times", 0, N-1)
//获得前N个最新登陆的用户Id列表
last_login_list = r.lrange("login:last_login_times", 0, N-1)
比如sina微博:
在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
4、Set
常用命令:
sadd,spop,smembers,sunion 等。
应用场景:
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Set 就是一个集合,集合的概念就是一堆不重复值的组合。利用Redis提供的Set数据结构,可以存储一些集合性的数据。
案例:
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
Set是集合,是String类型的无序集合,set是通过hashtable实现的,概念和数学中个的集合基本类似,可以交集,并集,差集等等,set中的元素是没有顺序的。
实现方式:
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
使用场景:
交集,并集,差集:(Set)
//book表存储book名称
set book:1:name ”The Ruby Programming Language”
set book:2:name ”Ruby on rail”
set book:3:name ”Programming Erlang”
//tag表使用集合来存储数据,因为集合擅长求交集、并集
sadd tag:ruby 1
sadd tag:ruby 2
sadd tag:web 2
sadd tag:erlang 3
//即属于ruby又属于web的书?
inter_list = redis.sinter("tag.web", "tag:ruby")
//即属于ruby,但不属于web的书?
inter_list = redis.sdiff("tag.ruby", "tag:web")
//属于ruby和属于web的书的合集?
inter_list = redis.sunion("tag.ruby", "tag:web")
获取某段时间所有数据去重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
5、Sorted Set
常用命令:
zadd,zrange,zrem,zcard等
使用场景:
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
和Set相比,Sorted Set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列,比如一个存储全班同学成绩的Sorted Set,其集合value可以是同学的学号,而score就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。另外还可以用Sorted Set来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
三、Redis实际应用场景
1、显示最新的项目列表
下面这个语句常用来显示最新项目,随着数据多了,查询毫无疑问会越来越慢。
SELECT * FROM foo WHERE ... ORDER BY time DESC LIMIT 10
在Web应用中,“列出最新的回复”之类的查询非常普遍,这通常会带来可扩展性问题。这令人沮丧,因为项目本来就是按这个顺序被创建的,但要输出这个顺序却不得不进行排序操作。类似的问题就可以用Redis来解决。比如说,我们的一个Web应用想要列出用户贴出的最新20条评论。在最新的评论边上我们有一个“显示全部”的链接,点击后就可以获得更多的评论。我们假设数据库中的每条评论都有一个唯一的递增的ID字段。我们可以使用分页来制作主页和评论页,使用Redis的模板,每次新评论发表时,我们会将它的ID添加到一个Redis列表:
LPUSH latest.comments <ID>
我们将列表裁剪为指定长度,因此Redis只需要保存最新的5000条评论:
LTRIM latest.comments 0 5000
每次我们需要获取最新评论的项目范围时,我们调用一个函数来完成(使用伪代码):
FUNCTION get_latest_comments(start, num_items):
id_list = redis.lrange("latest.comments",start,start+num_items - 1)
IF id_list.length < num_items
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
这里我们做的很简单。在Redis中我们的最新ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
2、排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,取最新N个数据的操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
热门,排行榜应用:
//将登录次数和用户统一存储在一个sorted set里
zadd login:login_times 5 1
zadd login:login_times 1 2
zadd login:login_times 2 3
//当用户登录时,对该用户的登录次数自增1
ret = r.zincrby("login:login_times", 1, uid)
//那么如何获得登录次数最多的用户呢,逆序排列取得排名前N的用户
ret = r.zrevrange("login:login_times", 0, N-1)
另一个很普遍的需求是各种数据库的数据并非存储在内存中,因此在按得分排序以及实时更新这些几乎每秒钟都需要更新的功能上数据库的性能不够理想。典型的比如那些在线游戏的排行榜,比如一个Facebook的游戏,根据得分你通常想要:
– 列出前100名高分选手
– 列出某用户当前的全球排名
这些操作对于Redis来说小菜一碟,即使你有几百万个用户,每分钟都会有几百万个新的得分。模式是这样的,每次获得新得分时,我们用这样的代码:
ZADD leaderboard <score> <username>
你可能用userID来取代username,这取决于你是怎么设计的。得到前100名高分用户很简单:
ZREVRANGE leaderboard 0 99
用户的全球排名也相似,只需要:
ZRANK leaderboard <username>
3、删除与过滤
我们可以使用LREM来删除评论。如果删除操作非常少,另一个选择是直接跳过评论条目的入口,报告说该评论已经不存在。 有些时候你想要给不同的列表附加上不同的过滤器。如果过滤器的数量受到限制,你可以简单的为每个不同的过滤器使用不同的Redis列表。毕竟每个列表只有5000条项目,但Redis却能够使用非常少的内存来处理几百万条项目。
4、按照用户投票和时间排序
排行榜的一种常见变体模式就像Reddit或Hacker News用的那样,新闻按照类似下面的公式根据得分来排序:score = points / time^alpha 因此用户的投票会相应的把新闻挖出来,但时间会按照一定的指数将新闻埋下去。下面是我们的模式,当然算法由你决定。模式是这样的,开始时先观察那些可能是最新的项目,例如首页上的1000条新闻都是候选者,因此我们先忽视掉其他的,这实现起来很简单。每次新的新闻贴上来后,我们将ID添加到列表中,使用LPUSH + LTRIM,确保只取出最新的1000条项目。有一项后台任务获取这个列表,并且持续的计算这1000条新闻中每条新闻的最终得分。计算结果由ZADD命令按照新的顺序填充生成列表,老新闻则被清除。这里的关键思路是排序工作是由后台任务来完成的。
5、处理过期项目
另一种常用的项目排序是按照时间排序。我们使用unix时间作为得分即可。 模式如下:
– 每次有新项目添加到我们的非Redis数据库时,我们把它加入到排序集合中。这时我们用的是时间属性,current_time和time_to_live。
– 另一项后台任务使用ZRANGE…SCORES查询排序集合,取出最新的10个项目。如果发现unix时间已经过期,则在数据库中删除条目。
6、计数
Redis是一个很好的计数器,这要感谢INCRBY和其他相似命令。我相信你曾许多次想要给数据库加上新的计数器,用来获取统计或显示新信息,但是最后却由于写入敏感而不得不放弃它们。好了,现在使用Redis就不需要再担心了。有了原子递增(atomic increment),你可以放心的加上各种计数,用GETSET重置,或者是让它们过期。例如这样操作:
INCR user:<id> EXPIRE
你可以计算出最近用户在页面间停顿不超过60秒的页面浏览量,当计数达到比如20时,就可以显示出某些条幅提示,或是其它你想显示的东西。
7、特定时间内的特定项目
另一项对于其他数据库很难,但Redis做起来却轻而易举的事就是统计在某段特点时间里有多少特定用户访问了某个特定资源。比如我想要知道某些特定的注册用户或IP地址,他们到底有多少访问了某篇文章。每次我获得一次新的页面浏览时我只需要这样做:
SADD page:day1:<page_id> <user_id>
当然你可能想用unix时间替换day1,比如time()-(time()%3600*24)等等。 想知道特定用户的数量吗?只需要使用
SCARD page:day1:<page_id>
需要测试某个特定用户是否访问了这个页面?
SISMEMBER page:day1:<page_id>
8、查找某个值所在的区间(区间无重合) :(Sorted Set)
例如有下面两个范围,10-20和30-40
- A_start 10, A_end 20
- B_start 30, B_end 40
我们将这两个范围的起始位置存在Redis的Sorted Sets数据结构中,基本范围起始值作为score,范围名加start和end为其value值:
redis 127.0.0.1:6379> zadd ranges 10 A_start (integer) 1 redis 127.0.0.1:6379> zadd ranges 20 A_end (integer) 1 redis 127.0.0.1:6379> zadd ranges 30 B_start (integer) 1 redis 127.0.0.1:6379> zadd ranges 40 B_end (integer) 1
这样数据在插入Sorted Sets后,相当于是将这些起始位置按顺序排列好了。现在我需要查找15这个值在哪一个范围中,只需要进行如下的zrangbyscore查找:
redis 127.0.0.1:6379> zrangebyscore ranges (15 +inf LIMIT 0 1 1) "A_end"
这个命令的意思是在Sorted Sets中查找大于15的第一个值。(+inf在Redis中表示正无穷大,15前面的括号表示>15而非>=15)查找的结果是A_end,由于所有值是按顺序排列的,所以可以判定15是在A_start到A_end区间上,也就是说15是在A这个范围里。至此大功告成。
9、交集,并集,差集:(Set)
//book表存储book名称
set book:1:name ”The Ruby Programming Language”
set book:2:name ”Ruby on rail”
set book:3:name ”Programming Erlang”
//tag表使用集合来存储数据,因为集合擅长求交集、并集
sadd tag:ruby 1
sadd tag:ruby 2
sadd tag:web 2
sadd tag:erlang 3
//即属于ruby又属于web的书?
inter_list = redis.sinter("tag.web", "tag:ruby")
//即属于ruby,但不属于web的书?
inter_list = redis.sdiff("tag.ruby", "tag:web")
//属于ruby和属于web的书的合集?
inter_list = redis.sunion("tag.ruby", "tag:web")
本文来自网络:https://www.cnblogs.com/xiaoxi/p/7007695.html
redis监控
- 摘要:redis-cli提供原生的监控视图1、redis-cli–stat查看当前连接的客户端数,连接数等2、redis-cli–bigkeys对当前占用内存最大的键值和平均的键值数据,也可以通过指定-i参数定时查看当前的视图情况。下图中为测试库,只对键值c做了操作,因此如下图中最大的键值为c3、redis-cli–scan提供和keys*相似的功能,查看当前的键值情况,可以通过正则表达如–pattern’user:*’进行键值的分析,并且配合shell命令进行相关的统计分
-
redis-cli提供原生的监控视图
1、redis-cli –stat查看当前连接的客户端数,连接数等
2、redis-cli –bigkeys对当前占用内存最大的键值和平均的键值数据,也可以通过指定-i参数定时查看当前的视图情况。下图中为测试库,只对键值c做了操作,因此如下图中最大的键值为c

3、redis-cli –scan提供和keys *相似的功能,查看当前的键值情况,可以通过正则表达如
–pattern ‘user:*’
进行键值的分析,并且配合shell命令进行相关的统计分析redis-cli提供原生的Monitor监控命令以及基于该命令的扩展监控框架
1、redis-cli monitor打印出所有sever接收到的命令以及其对应的客户端地址

2、RedisLive是基于python3实现的可视化监控界面
https://github.com/nkrode/RedisLive
http://www.nkrode.com/article/real-time-dashboard-for-redis
3、redis-stat是基于ruby实现的可视化监控界面
https://github.com/junegunn/redis-stat
4、redis-faina是基于python2实现的可视化监控界面,监控100行命令

https://github.com/facebookarchive/redis-faina
本文来自网络:https://www.aliyun.com/jiaocheng/452905.html
phpredis中的connect和pconnect
本文转自网络:https://blog.csdn.net/u013474436/article/details/53118475
现在不管是在缓存方面,还是NoSQL方面,Redis很火也很流行,但是使用方面的经验不是很多,包括Redis的一些优化配置,还有使用Redis的一些技巧和经验都没有一个官方的指导,所以在网上能搜索到很多相关的东西,但是发现不一定完全匹配自己遇到的一些问题,而且有的文章只是告诉你要这么做,但是没有深究到底是为什么?
最近碰到一个项目的优化,该项目其实逻辑很简单,大的结构就是处理用户的请求,然后读Redis,返回对应的数据。而问题的所在在于该项目有个特点,就是存在整点效应——平时访问量比较低,服务器压力不大,但是整点的时候并发能够达到平时的4-5倍,服务器完全抗不住。所以我们就慢慢梳理整个项目的架构,还有流程,想从中发现问题的所在。
为了先解决并发高服务器负载过高的问题,我们首先分析了…(话扯远了,背景就介绍到这里,呵呵。。)
首先先介绍下connect和pconnect的区别。
connect:脚本结束之后连接就释放了。
pconnect:脚本结束之后连接不释放,连接保持在php-fpm进程中。
为了验证这点,我们可以写个脚本测试一下。
其中服务器是nginx,php-fpm采用静态方式,因为动态方式下php-fpm的进程数量可能会变化,所以为了简单我们采用静态方式启动。
其中php-fpm的数量我们设置成5个。
下面的脚本测试使用connect的情况,我们让脚本连接到redis,然后休眠10s。
<?php
$app = new App ();
$app->get ( '/', function () {
$redis = new Redis ();
$redis->connect ( '127.0.0.1' );
sleep(10);
echo 'Hello World';
// $redis->close ();
} );
return $app;然后我们运行5个请求:
curl http://localhost:8081这时候我们可以看下redis中的connect_clients:
$ redis-cli info | grep connected_clients
connected_clients:14等脚本运行完毕之后我们再看一下connect_clients:
$ redis-cli info | grep connected_clients
connected_clients:9之前建立的redis连接资源被释放了。
我们修改上面的代码,把connect改成pconnect:
<?php
$app = new App ();
$app->get ( '/', function () {
$redis = new Redis ();
$redis->pconnect ( '127.0.0.1' );
sleep(10);
echo 'Hello World';
// $redis->close ();
} );
return $app;和上面同样的操作,发现脚本脚本运行结束后connected_clients还是14:
$ redis-cli info | grep connected_clients
connected_clients:14这说明脚本运行结束后,redis连接资源并没有释放,而是由php-fpm进程保持(可以通过 kill php-fpm看到,当脚本停止运行后连接释放)
所以使用pconnect代替connect,可以减少频繁建立redis连接的消耗。
另外,使用pconnect还可以减少同一个进程(php-fpm)频繁建立连接的消耗,可以通过以下代码验证:
使用connect的情况:
<?php
$redis1 = new Redis();
$redis1->connect('127.0.0.1');
sleep(5);
$redis2 = new Redis();
$redis2->connect('127.0.0.1');
sleep(5);
//$redis->close();
//$redis2->close();运行上述脚本,会发现connect_clients会增加2个。
使用pconnect的情况:
<?php
$redis1 = new Redis();
$redis1->pconnect('127.0.0.1');
sleep(5);
$redis2 = new Redis();
$redis2->pconnect('127.0.0.1');
sleep(5);
//$redis->close();
//$redis2->close();而运行上述代码,connect_clients只会增加1个,这说明在一个进程中,pconnect是可以保持redis连接状态提供复用的。
CentOS7 linux下yum安装redis以及使用
一、安装redis
1、下载fedora的epel仓库
|
1
|
yum install epel-release |
2、安装redis数据库
|
1
|
yum install redis |
3、安装完毕后,使用下面的命令启动redis服务
|
1
2
3
4
5
6
7
8
|
# 启动redisservice redis start# 停止redisservice redis stop# 查看redis运行状态service redis status# 查看redis进程ps -ef | grep redis |
5、设置redis为开机自动启动
|
1
|
chkconfig redis on 或 systemctl enable redis.service |
6、进入redis服务
|
1
2
3
4
|
# 进入本机redisredis-cli# 列出所有keykeys * |
7、防火墙开放相应端口
|
1
2
3
4
5
6
7
8
|
# 开启6379/sbin/iptables -I INPUT -p tcp --dport 6379 -j ACCEPT # 开启6380/sbin/iptables -I INPUT -p tcp --dport 6380 -j ACCEPT # 保存/etc/rc.d/init.d/iptables save# centos 7下执行service iptables save |
二、修改redis默认端口和密码
1、打开配置文件
|
1
|
vi /etc/redis.conf |
2、修改默认端口,查找 port 6379 修改为相应端口即可

3、修改默认密码,查找 requirepass foobared 将 foobared 修改为你的密码

4、使用配置文件启动 redis
|
1
|
redis-server /etc/redis.conf & |
5、使用端口登录
|
1
|
redis-cli -h 127.0.0.1 -p 6179 |
6、此时再输入命令则会报错

7、输入刚才输入的密码
|
1
|
auth 111 |

8、停止redis
命令方式关闭redis
|
1
2
|
redis-cli -h 127.0.0.1 -p 6179shutdown |
进程号杀掉redis
|
1
2
|
ps -ef | grep rediskill -9 XXX |
三、使用redis desktop manager远程连接redis
1、访问如下网址下载redis desktop manager
|
1
2
|
<a href="https://redisdesktop.com/download" target="_blank">https://redisdesktop.com/download</a> |
2、安装后启动,新建一个连接

3、填写如下信息后点击“Test Connection”测试是否连接成功

4、如果长时间连接不上,可能有两种可能性
a)bind了127.0.01:只允许在本机连接redis
b)protected-mode设置了yes(使用redis desktop manager工具需要配置,其余不用)
解决办法:
|
1
2
3
4
5
|
# 打开redis配置文件vi /etc/redis.conf # 找到 bind 127.0.0.1 将其注释# 找到 protected-mode yes 将其改为protected-mode no |
5、重启redis
|
1
2
|
service redis stopservice redis start |
6、再次连接即可

参考:
https://www.cnblogs.com/wiseroll/p/7061673.html
http://blog.csdn.net/gebitan505/article/details/54602662
http://blog.csdn.net/lh2420124680/article/details/75426144
本文转发自:https://www.cnblogs.com/rslai/p/8249812.html
PHP 使用 Redis(PHP redis 扩展)
安装好redis了,PHP 怎么使用呢?默认情况下PHP是需要安装扩展才能调用redis的
PHP redis 驱动:下载地址为:https://github.com/phpredis/phpredis/releases。我选择安装的是:4.1.1
- ssh 登录服务器
- 下载&安装扩展
如果你是 PHP7 版本,则需要下载指定分支:
git clone -b php7 https://github.com/phpredis/phpredis.git我的是PHP5
wget https://github.com/phpredis/phpredis/archive/4.1.1.tar.gz tar -zxvf 4.1.1.tar.gz ll cd phpredis-4.1.1/ #生成 configure /alidata/server/php/bin/phpize ./configure --with-php-config=/alidata/server/php/bin/php-config #make 过程耐心等待哦 make make install - 配置
找到php.ini文件vi /alidata/server/php-5.5.7/etc/php.ini添加
extension_dir = /alidata/server/php/lib/php/extensions/no-debug-non-zts-20121212/ extension=redis.so重启php-fpm
/etc/init.d/php-fpm restart大功告成 测试下吧:
- 测试
<?php $redis = new Redis(); $redis->connect('127.0.0.1', 6379); echo "OK"; echo "Server is running: " . $red->ping(); ?>
centos下安装redis
- 去哪里下 http://www.redis.cn/download.html 或 https://redis.io/download (这两个网站是你以后学习redis.cn的大本营 )找到对应的下载链接 比如 http://download.redis.io/releases/redis-4.0.11.tar.gz
- 下载 wget http://download.redis.io/releases/redis-4.0.11.tar.gz 下载到服务器
- 解压 tar -zxvf redis-4.0.11.tar.gz
- 安装
cd redis-4.0.11
make
make install (安装成功)
Redis没有其他外部依赖,安装过程很简单。编译后在Redis源代码目录的src文件夹中可以找到若干个可执行程序,安装完后,在/usr/local/bin目录中可以找到刚刚安装的redis可执行文件。

- 运行 cd /usr/local/bin
#直接运行
redis-server通过初始化脚本启动Redis
在Redis源代码目录的utils文件夹中有一个名为
redis_init_script的初始化脚本文件。需要配置Redis的运行方式和持久化文件、日志文件的存储位置。步骤如下:1、配置初始化脚本
首先将初始化脚本复制到/etc/init.d 目录中,文件名为 redis_端口号,其中端口号表示要让Redis监听的端口号,客户端通过该端口连接Redis。然后修改脚本第6行的REDISPORT变量的值为同样的端口号。
2、建立以下需要的文件夹。
目录名 Value /etc/redis 存放Redis的配置文件 /var/redis/端口号 存放Redis的持久化文件 3、修改配置文件
首先将配置文件模板(redis-4.0.11/redis.conf)复制到/etc/redis 目录中,以端口号命名(如“6379.conf”),然后按照下表对其中的部分参数进行编辑。
参数 值 说明 daemonize yes 使Redis以守护进程模式运行 pidfile /var/run/redis_端口号.pid 设置Redis的PID文件位置 port 端口号 设置Redis监听的端口号 dir /var/redis/端口号 设置持久化文件存放位置 现在也可以使用下面的命令来启动和关闭Redis了
/etc/init.d/redis_6379 start /etc/init.d/redis_6379 stop输入命令:ps -ef|gref redis 查看redis 是否启动了
- 让redis 随机启动
vim /etc/init.d/redis_6379在打开的redis初始化脚本文件头部第四行的位置,追加下面两句
# chkconfig: 2345 90 10 # description: Redis is a persistent key-value database然后运行(设置开机启动)
chkconfig redis_6379 on通过上面的操作后,以后也可以直接用下面的命令对Redis进行启动和关闭了,如下
service redis_6379 start service redis_6379 stop经过上面的部署操作后,系统重启,Redis也会随着系统自动启动,并且上面的步骤里也配置了Redis持久化,下次启动系统或Redis时,有缓存数据不丢失的好处。
- 如果停止redis
考虑到 Redis 有可能正在将内存中的数据同步到硬盘中,强行终止 Redis 进程可能会导致数据丢失。正确停止Redis的方式应该是向Redis发送SHUTDOWN命令,方法为:redis-cli SHUTDOWN当Redis收到SHUTDOWN命令后,会先断开所有客户端连接,然后根据配置执行持久化,最后完成退出。
Redis可以妥善处理 SIGTERM信号,所以使用kill Redis进程的 PID也可以正常结束Redis,效果与发送SHUTDOWN命令一样。

- 结束啦(本文参考了一些网络资料)